情シスの仕事をちょっと楽にするためのGoogleドライブ管理ツールを作ってみました。
各機能ごとにコードを書いて解説しても良いのだけど、ここにたどり着いた人はすぐに使えるサンプルを欲しているはず。 ということでスプレッドシートごと公開します。
コピー作成してご利用ください。
Googleドライブ管理ツール_1.0.3 - Google スプレッドシート
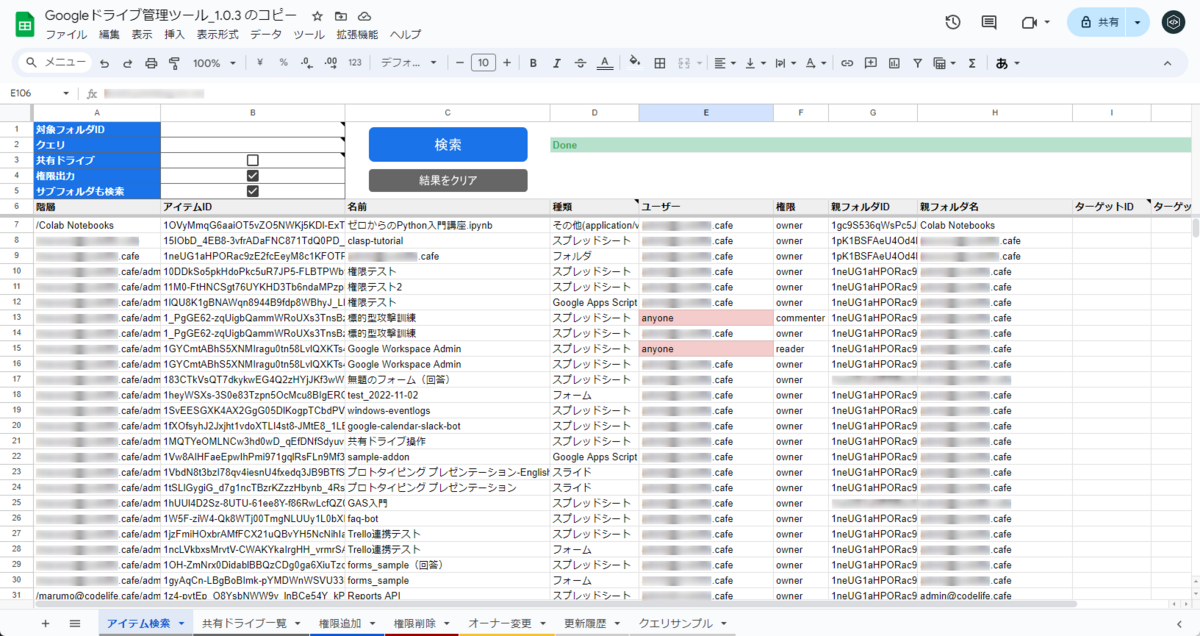
検索機能
- 対象のフォルダIDやクエリを設定して「検索」ボタンを押すと配下のアイテムを検索してスプレッドシート上にリストアップ
- 権限出力をONにするとどのユーザーが何の権限を持っているかも表示
- サブフォルダも検索をONにすると対象フォルダの中のフォルダも再帰的に検索して表示
- 共有ドライブの検索にも対応
- レジューム機能付きなので大量のファイルがあってもひたすら検索し続ける
権限変更機能
- アイテムID、ユーザー、権限レベルを指定して権限を一括で追加する
- アイテムID、ユーザー、権限レベルを指定して権限を一括で削除する
- アイテムID、新オーナーを指定してオーナーを一括で変更する
などの機能が詰め込まれています。使っていてお気づきの点や機能追加のご要望があればコメントかメールでご連絡ください。
- アイテム検索
- 設定内容
- 出力内容
- 共有ドライブ一覧
- 出力内容
- 権限追加
- 権限削除
- オーナー変更